▶ STL이란?
ㆍ STL은 Standard Templae Library의 약자로 C++의 표준 라이브러리중 하나
ㆍ다양한 데이터구조와 알고리즘을 템플릿으로 제공하는 라이브러리
ㆍ stl은 크게 컨테이너, 반복자, 알고리즘로 나뉘고 상세하게는 함수객체와 할당자가 추가된다.
1. 컨테이너 (Containers)
ㆍ 다양한 데이터 구조를 표현하는 클래스 템플릿
ex) 시퀸스 컨테이너 : vector, List
컨테이너 어뎁터 : queue, stack
연관 컨테이너: map,set
2. 반복자
ㆍ 컨테이너의 원소들에 접근할 수 있는 일반회된 포인터 역할을 하는 객체
ㆍ 컨테이너의 요소를 순회하는 인터페이스를 제공하며 이를 통해 다양한 타입의 컨테이너를 동일한 방식으로 접근할 수 있다.
3. 알고리즘
ㆍ 정렬, 검색, 수치 연산 등 일반적인 알고리즘 함수를 템플릿 형태로 제공
4. 함수 객체
ㆍ 함수처럼 동작하는 객체를 의미
※ operator() 키워드
ㆍ "함수 호출 연산자"를 오버로딩하는 연산자
ㆍ 해당 객체를 함수처럼 호출할 수 있게 된다.
5. 할당자
ㆍ 메모리 할당 및 함수 해제 방식을 추상화 한 것으로 개발자가 원하는 방식으로 메모리를 관리할 수 있게 해줌
▶ vector 란?
- 시퀀스 컨테이너, 배열기반 컨테이너 -
ㆍ 동적 배열로 구현되어 있고 원소들은 메모리 공간에 연속적으로 저장되어 있다.
ㆍ 인덱스 접근을 하용하며 O(1)의 시간 복잡도를 가진다.
ㆍ 원소를 추가 / 삭제 하는것은 배열의 끝에서만 효율적이게 이루어지며 중간에서 삽입,삭제 하는 것은 O(n)의 시간복잡도를 가진다.
ㆍ 원소의 추가 삭제는 push_back(), pop_back() , insert() erase()등의 함수로 가능하며 용량의 사이즈는 size(),capacity()로 확인이 가능하며 risize(), reserve()등의 함수로 크기나 용량을 조절할 수 있다.
ㆍ 메모리가 가득 찼을 때 이 전의 메모리를 삭제하고 원소를 복사 한 뒤 메모리를 재할당 하는 방식을 체텍
※ push_back , emplace_back
push_back 과 emplace_back의 차이점?
| 특징 | push_back | emplace_back |
| 객체 생성 방식 | 이미 생성된 객체를 복사 또는 이동 | 생성에 필요한 인자를 직접 전달하여 생성 |
| 성능 | 복사 또는 이동 오버헤드 발생 가능 | 불필요한 복사 및 이동 없음 |
새로운 객체를 추가할땐 emplace_back을 쓰는게 더 효율적일 수 있겠다. 허나 이미 존재하는 객체를 추가할 경우 push_back을 사용하면 되겠다.
▶ list란?
- 시퀀스 컨테이너, 배열기반 컨테이너 -
ㆍ 양방향 연결 리스트로 구현되어 있다
ㆍ 각 노드들은 이전노드와 다음노드를 가리키는 포인터를 가지고 있다.
ㆍ 인덱스 접근을 지원하지 않으며 순차 접근만 가능하다.
ㆍ 따라서 특정 위치의 원소에 접근하려고 하면 처음부터 순회해야 하므로 O(n)의 시간 복잡도 발생
ㆍ 어디서든 삽입과 삭제가 O(1)의 시간안에 가능
ㆍ 각 요소가 독립적인 메모리 공간에 저장되므로 크기 변경시 재할당 없이 메모리 관리가 가능
※ 따라서 원소에 자주 접근해야 한다면 vector를, 중간에서 삽입/삭제가 빈번하게 일어나고 크기 변동이 자주 일어난다면 list를 채용하는 것 이 좋겠다.
▶ deque 덱 에 대해
- 시퀀스 컨테이너, 배열기반 컨테이너 -
ㆍ 양쪽 끝에서 삽입과 삭제가 모두 가능한 컨테이너
ㆍ 필요에 따라 메모리를 자동으로 재할당
ㆍ 배열 기반의 컨테이너로 인덱스 접근이 가능하며 O(1)의 시간복잡도를 가짐
ㆍ 중간에서 삽입 / 삭제 하는 경우 Vector에 비해 효율이 약간 더 우수
why? ) vector는 앞에서 원소를 추가하는 것이 불가능하기 때문에 모든 원소를 뒤쪽으로 밀어야만 하는데 deque는 앞뒤 삽입 삭제가 가능하기 때문에
ㆍ 내부적으로 여러개의 고정된 크기를 가진 배열을 사용해 데이터를 저장해 실제 메모리 구조는 비연속적이지만 사용자 입장에서는 연속된 메모리 공간처럼 사용할 수 있다.
ㆍ 필요에 따라 새로운 메모리 블록을 추가하므로 동적으로 크기가 변동되어도 기존 요소들을 복사하지 않아도 된다.

※ 단점 - vector와 비교
- 메모리 오버헤드: std::deque는 여러 개의 작은 메모리 블록을 사용하여 구성되기 때문에, 이들 각각에 대한 관리 비용이 추가로 발생합니다. 따라서 std::vector에 비해 메모리 사용량이 약간 더 클 수 있습니다.
- 원소 접근 시간: std::deque는 비연속적인 메모리 공간에 데이터를 저장하기 때문에, 인덱스를 통한 원소 접근 시간이 일반적으로 std::vector보다 조금 느릴 수 있습니다.
- 캐시 지역성(Cache Locality) 부족: 비연속적인 메모리 구조로 인해 CPU 캐시 효율성이 상대적으로 낮아질 수 있습니다. 이는 순차적인 데이터 접근 성능을 약화시킬 수 있습니다.
- 반복자 유효성: std::vector와 달리 push_front()나 push_back() 연산 후에도 기존의 반복자들은 유효하게 유지됩니다. 그러나 중간 위치에서 원소를 추가하거나 제거하는 경우 해당 위치부터 끝까지의 모든 반복자가 무효화됩니다.
▶ queue에 대해
※ 컨테이너 어댑터란? - 기본적인 STL컨테이너 위에 더 특화된 데이터 구조를 제공하는것을 의미
ㆍ 선입선출 원칙에 따라 동작하고 Deque를 내부 컨테이너로 사용하지만 List와도 붙어서 사용할 수 있다.
ㆍ front()함수를 지원하는 컨테이너라면 다 가능하다
ㆍ 반복자를 지원하지 않음
사용예시: 작업 스케줄링, 버퍼관리, BFS(너비우선탐색) 등 선입선출 원칙을 따르는 데이터관리가 필요한 경우
실생활 예시: 은행에서 자신의 차례를 기다리며 줄을 선다.

▶ "priority queue"에 대해
- 컨테이너 어뎁터 -
ㆍ 각 원소가 우선순위를 가지고 있는 자료구조로 우선순위가 가장 높은 데이터가 가장 먼저 나오는 특성을 가짐
ㆍ 내부적으로 heap(힙) 자료구조를 이용해 구현되어 있다.
ㆍ 기본적으로 내림차순(최대힙) 으로 정렬되어 있어, 가장 높은 값이 우선순위가 가장 높다.
ㆍ 만약 오름차순(최소힙) 으로 우선순위를 정하고 싶다면 선언 시 비교 함수를 변경하여 사용할 수 있다.


ㆍ 다익스트라, A*, 등에서 사용되며 시뮬레이션, 작업스케줄링 등에서 사용됨
▶ Heap이란?
ㆍ 최대값 및 최소값을 찾아내는 연산을 빠르게 하기 위해 고안된 완전이진트리를 기본으로 한 자료 구조
※ 아래는 최대힙의 완전이진트리 내부 구조 과정

ㆍ 30이라는 값을 삽입한다.


ㆍ 위와 같은 과정을 거쳐 최대값이 최상위로 이동할 때 까지 과정을 반복한다.
※ 최대 힙의 특성.txt
ㆍ 임의의 서브트리에서 루트가 되는 노드를 잡으면 항상 [ 서브트리 < 루트 ] -> 최대값이 최상단
ㆍ 주의할점은 힙의 자식노드에서는 [왼쪽 < 오른쪽] 과 같은 식은 성립하지 않는다.
-> 왼쪽 오른쪽에 무슨 노드가 오건 관계없이 해당하는 서브트리에서 루트노드보다 작은 값이면 된다.
▶ stack에 대해
- 컨테이너 어뎁터 -
ㆍ 스택은 후입선출 원칙에 따라 동작하므로 가장 마지막에 들어온 요소가 가장 먼저 나간다.
ㆍ 내부적으로 deque로 구현되어 있으며 vector와 list처럼 해당 컨테이너가 back함수를 지원한다면 다른 컨테이너와도 호환 가능
ㆍ 반복자를 지원하지 않음
사용 예시 : 웹페이지의 뒤로가기, DFS(깊이우선탐색), 컴파일러나 인터프리터의 함수 호출 스택 관리

▶ map에 대해
- 연관 컨테이너 -
※ 연관컨테이너란?: 내부적으로 트리 구조를 활용하여 데이터를 정렬된 상태로 저장 하는 컨테이너
※ 내부적으로 자가 균형 이진 탐색트리인 레드-블랙 트리를 사용하여 데이터를 저장
ㆍ 키와 값을 쌍으로 저장하는 자료구조, 키는 원소를 식별하는데 사용 되며 각 키는 유일해야한다.
ㆍ 키를 기준으로 원소를 자동 정렬하며 기본적으로 오름차순으로 정렬되어 있지만 사용자 정의 비교 함수로 원하는 방식으로 정렬 가능
ㆍ원소의 삽입, 삭제에 따라 동적으로 크기 조절
ㆍ 삽입,삭제,검색 등의 시간이 O(logN)으로 빠르다
ㆍ 반복자를 지원한다.
▶ 맵 내부구조가 어떤 자료구조로 되어있는지?
ㆍ std::map의 내부 구조는 자가 균형 이진 탐색 트리인 Red-Black Tree로 구현되어 있다.

Red-Black Tree는 이진 탐색 트리의 한 종류로, 다음과 같은 특성을 가진다
1. 모든 노드는 빨강 혹은 검은색을 가짐
2. 루트노드는 반드시 검정색
3. 모든 리프노드(NULL)는 검정색
4. 노드의 색이 빨강이라면 그 노드의 자식 노드는 반드시 검정색
5. 어떤 노드로부터 그 노드의 자손인 리프노드까지의 경로에는 동일한 수의 검정 노드가 있다.
ㆍ 이러한 특성 덕분에 레드-블랙 트리는 상대적으로 균형잡힌 형태를 유지하며 트리의 높이를 log(n)으로 유지할 수 있다.
ㄴ 삽입 삭제 검색 등의 연산을 항상 O(log n)
새로운 값을 삽입할 시 새 노드는 빨간색으로 설정되고 이진 탐색 트리의 속성에 따라 적잘한 위치에 삽입된다.
ㄴ 그러나 이렇게 설정하면 레드 -> 레드 구조가 나올 수 있다..
ㆍ 이러한 문제를 해결하기 위해 Recoloring 과정과 Restructing과정을 거친다
※ Restructing과정

ㆍ 이 과정에서 회전(rotation) 연산이 이루어진다.
ㆍ 트리의 균형을 다시 맞추기 위해 트리의 일부분을 재구조화 하여 트리의 균형을 회복하는 과정
ㆍ Left Rotation과 Right Rotation이 있다.
- 좌회전시 오른쪽 자식 노드의 왼쪽 자식 노드를 부모 노드의 오른쪽 자식으로 연결
- 우회전시 왼쪽 자식 노드의 오른쪽 자식 노드를 부모 노드의 왼쪽 자식으로 연결
※ Recoloring 과정
ㆍ 노드의 색상을 변경하는 연산으로 특히 노드의 부모와 삼촌이 모두 빨간색인 경우에 수행됨
ㄴ 이 경우 부모와 삼촌을 검은색으로 바꾸고 조부모를 빨간색으로 변경한다.
-> 조부모 노드가 루트 노드가 아니라면 그 위로 레드블랙 트리가 깨질 수도 있다.
ㆍ 위 과정을 반복하여 레드 블랙 트리의 균형이 맞을 때 까지 반복한다.
▶ 레드블랙트리의 장단점?
장점
균형 유지: Red-Black Tree는 삽입과 삭제 연산 후에도 트리의 균형을 유지합니다. 이는 검색, 삽입, 삭제 연산이 항상 최악의 경우에도 O(log n) 시간 복잡도를 가질 수 있음을 보장합니다.
효율적인 검색 연산: Red-Black Tree는 이진 탐색 트리이므로 중위 순회(In-order traversal)를 사용하여 정렬된 순서대로 요소를 얻을 수 있습니다.
다양한 사용 사례: Red-Black Tree는 맵(map), 세트(set), 멀티맵(multimap), 멀티세트(multiset) 등 다양한 추상 데이터 타입(ADT) 구현에 사용됩니다.
단점
복잡성: Red-Black Tree의 구현은 상대적으로 복잡합니다. 삽입과 삭제 시에 노드의 색깔 변경 및 회전 등 추가적인 작업이 필요하며, 그 과정에서 특정 규칙을 준수해야 합니다.
메모리 오버헤드: 각 노드가 자신의 색깔(red or black) 정보를 저장해야 하므로 추가 메모리가 필요합니다.
삽입 및 삭제 비용: 노드를 삽입하거나 삭제할 때마다 균형 유지 작업을 위한 부가적인 연산(회전 등)이 필요하므로, 다른 종류의 이진 탐색 트리(BST)나 해시 테이블(hash table)과 비교할 때 상대적으로 높은 비용이 발생할 수 있습니다.
▶ set에 대해
- 연관 컨테이너 -
ㆍ 중복을 허용하지 않는 원소들을 저장하는 자료구조로 요소들은 오름차순으로 자동으로 정렬된다.
ㆍ 중복되어 삽입 될 시 첫번째 삽입만이 성공하고 나머지는 실패한다
ㆍ 기본적으로 오름차순 정렬이지만 사용자 정의 비교함수로 정렬 순서를 바꿀 수 있다.
ㆍ O(logn)의 시간 복잡도 - > 내부적으로 레드 블랙 트리로 구현됨
ㆍ 동적 크기 조정
ㆍ 반복자 지원
insert(): 세트에 새로운 요소를 추가합니다.
erase(): 세트에서 요소를 삭제합니다.
find(): 주어진 값과 일치하는 요소를 찾아 iterator 형태로 반환합니다.
▶ STL에서 set에서 find를 하면 벡터처럼 시퀀스 컨테이너도 아닌데 빨리 찾아지는 이유
ㆍ 내부적으로 자가균형 이진 탐색 트리인 red-black tree로 구현되어 있기 때문에
ㆍ 검색 하려는 값과 트리의 루트 노드를 비교하고, [찾으려는 값 < 루트] 라면 왼쪽 서브트리로 [찾으려는값 > 루트] 라면 오른쪽 서브트리로 이동하는 방식으로 감색함
ㆍ 전체 노드 수가 n개일 때 최대 O(log n)의 시간 복잡도를 가짐
ㆍ 따라서 STL set에서 find() 함수는 선형적인 데이터 구조보다 일반적으로 빠르게 원소를 찾을 수 있다.
▶ function에 대해
ㆍ 함수포인터, 람다, 함수객체 등 다양한 종류의 호출 가능 객체를 저장하고 관리할 수 있는 기능을 제공한다.
-> 내부적으로 템플릿을 사용해 구현되어 있기 때문
ㆍ 저장할 수 있는 객체의 타입을 컴파일 시점에 체크하기 때문에 런타임에서 오류가 발생하는 것을 방지할 수 있다.
ㆍ 사용하려면 반환 타입과 매개변수 타입을 입력해야 한다
std::function<int(int,int)>-> int형 2개를 매개변수로 받고 int형을 반환하겠다.
ㆍ 장점으론 다양한 종류의 호출가능한 객체를 동일하게 다룰 수있으므로 재사용성이 크게 증가한다는 점
※ ▶ 같이 알아둘것 : bind 와 placeholders::_n
void print(int a, int b)
{
std::cout << a << ", " << b << std::endl;
}
int main()
{
function<void(int)> print_one = bind(print,1,placeholders::_1);
print_one(2); // 출력: 1, 2
return 0;
}
bind
ㆍ 주어진 함수, 또는 함수 객체의 매개변수 일부를 고정하거나 재정렬 하여 새로운 함수를 생성한다.
function<void(int)> new_func = bind(print, 1, 2);print 함수에 매개변수 1과 2 값을 고정한다.
placeholders
ㆍbind함수와 함께 사용되는 플레이스홀더
ㆍ placeholders::_1 , placeholders::_2 ........ placeholders::_N 의 형태로 사용
function<void(int)> print_one = bind(print,1,placeholders::_1);ㆍ 첫번째 인자로 1을 bind로 고정하고 n번째 자리 인자는 고정으로 두지 않고 동적으로 받아서 사용해겠다. 라는 의미
▶ 콜백함수란?
ㆍ 특정 이벤트가 발생하거나 특정 조건이 만족되었을때 시스템에 의해 호출되는 함수
ㆍ 어떤 작업이 비동기적으로 수행되고 그 결과를 나중에 처리하려 할 때 이러한 작업의 완료 시점에서 호출될 함수를 등록해두면 그것이 콜백함수
▶ 람다식 ( C++ 11부터 도입된 기능)
기본 식
[캡처목록](매개변수 목록) -> 반환타입 { 함수 본문 }
ㆍ 익명 함수를 정의하고 사용할 수 있게 해주는 기능
ㆍ 사용할 상황 : 간단한 함수를 한 번만 사용하거나, 함수를 인자로 받는 함수에 인자를 전달하거나(콜백), 함수 객체를 반환하는 함수를 작성할 때
1. 캡처목록 : 람다 식이 사용할 수 있는 외부 범위의 변수들을 명시
[] : 아무것도 캡처하지 않겠다를 의미, [=]
[=] : 외부 범위의 모든 변수를 값으로 캡처하겠다.
ㆍ 람다 식이 생성될 때 캡처한 변수의 현재 값을 복사 -> 람다식 내부 사용
ㆍ 기본적으로 이렇게 캡처하 값은 람다 식 내부에서 변경할 수 없으나 mutable 키워드를 사용하면 변경할 수 있게 된다.
-> 값을 복사해서 사용하는 것 이기 때문에 외부의 변수에는 영향을 미치지 않는다.
[&] : 외부 범위의 모든 변수를 참조로 캡처하겠다.
ㆍ 람다식 내부에서 원래 변수를 직접 참조하여 사용한다, 따라서 람다 식 내부에서 이 값을 변경하면 원래 변수의 값도 함께 변동된다.
[a,&b] : 특정 변수만을 캡처하겠다
2. 매개변수 목록 : 람다 식이 받는 인자를 명시, 일반 함수의 매개변수와 동일한 방식으로 작성
3. 반환 타입 : 람다 식의 반환 타입을 명시, 이 부분은 생략할 수 있으며 생략시 컴파일러가 함수 본문을 분석하여 반환타입을 추론
4. 함수 본문 : 람다식이 수행할 연산을 명시
▶ 직교좌표와 극좌표?
1. 직교좌표

ㆍ 가장 일반적으로 사용되는 좌표 체계
ㆍ 두 축이 서로 직각을 이루는 좌표계
ㆍ 2차원 공간에서는 (x , y) 처럼 두 값으로 각각의 좌표를 나타냄
ㆍ 각 축은 수평과 수직 방향을 나타냄
2. 극좌표
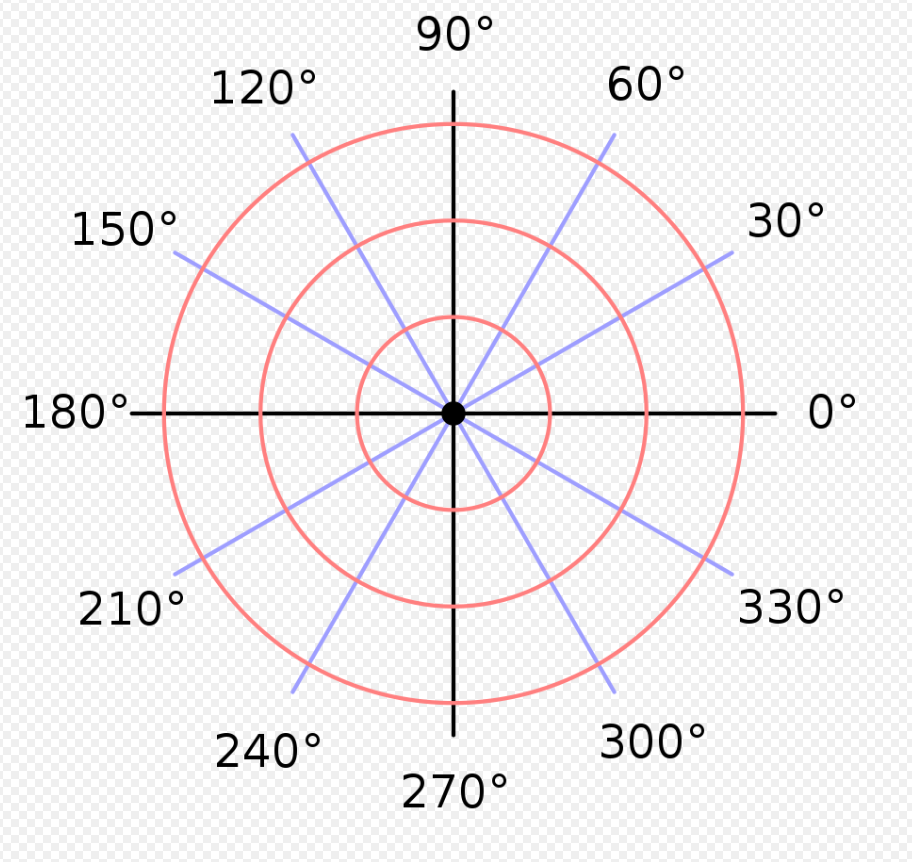
ㆍ 원점에서의 거리와 (반지름) 원점에서 점까지의 각도(θ)로 점을 나타내는 좌표계
ㆍ 2차원 공간에선 (r , θ) 로 표현
ㆍ 원형이나 회전에 관련된 문제를 다룰 때 유용함
극좌표를 직교좌표로 변환하는 공식 : x = r*cos(θ) y = r*sin(θ)
float radiusIncrement = 100;
for (int i = 1; i <= 2; ++i)
{
float angleIncrement = (PI * 2) / (10 * i);
float radius = radiusIncrement * i;
for (float angle = 0; angle < PI * 2; angle += angleIncrement)
{
_thorn->fire(_thornPos.x + cos(angle) * radius,
_thornPos.y + sin(angle) * radius, 64);
}
}극좌표 -> 직교좌표 코드 예시
원형 패턴을 x,y좌표계로 표현하기 위해서 극좌표를 직교좌표로 변경해 fire함수에 넘겨주는 부분.
'C++프로그래밍 > 이론 정리' 카테고리의 다른 글
| unordered_map과 해시 (0) | 2023.12.07 |
|---|---|
| 상수에 대해 (const) (0) | 2023.12.06 |
| 형변환 연산자 (0) | 2023.12.04 |
| vitrual키워드와 가상함수테이블 (0) | 2023.11.29 |
| 쓰레드, 코루틴, 델리게이트와 스마트포인터 (0) | 2023.10.12 |